
tg-me.com/knowledge_accumulator/85
Last Update:
Introducing Symmetries to Black Box Meta Reinforcement Learning [2021] - применяем VSML на RL-задачах
Одна из статей, про которую я рассказывал выше, понравилась мне настолько, что я решил прочитать все статьи её автора за последние годы, и там я нашёл кучу интересного на тему мета-обучения.
В данной работе в лоб применяют VSML + генетику (называют SymLA) в нескольких сериях экспериментов:
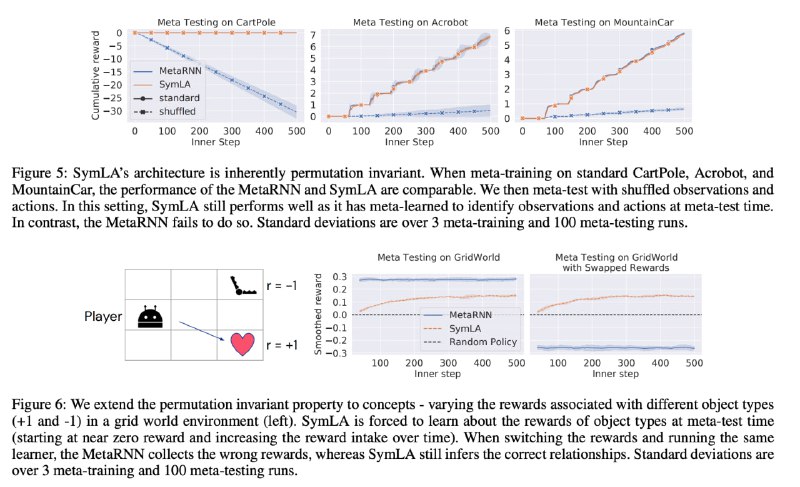
1) Классические элементарные RL-задачи с перемешиванием
Суть эксперимента в том, что мы обучаем модель обучаться на задаче, а затем мета-тестируем на той же задаче, но с перемешанными входами и действиями. Бейзлайн от этого плавится, а VSML в принципе инвариантна к перестановкам (на новой задаче), поэтому у неё всё хорошо
2) Лабиринт с капканом и сердечком
Агент управляет персонажем в маленькой координатной сетке, на которой есть положительная и отрицательная награда. Модель мета-обучают, а при мета-тестировании награды меняют местами.
Бейзлайн жёстко переобучается под сбор сердечка, и после того, как оно начинает давать отрицательную награду, он продолжает его собирать. У VSML кривые обучения в обоих случаях одинаковые, то есть она всю информацию извлекает в процессе мета-тестирования
3) Смена RL-задачи на радикально другую
Всё просто - модель обучают на Gridworld (задача из пункта 2), а применяют на CartPole - совсем непохожей задаче. Картина та же самая.
Вполне вероятно, что данная технология сейчас находится в положении нейросетей в конце 1990-х. На MNIST (снова) успешно применили, но на большей задаче применить пока нереально. Не знаю, какие тут нужны вычислительные ресурсы, и есть ли они хотя бы у Deepmind, но я думаю, тот, кто первый успешно применит это на Atari, начнёт новую эру в ML. У нас будут претренированные алгоритмы, которые все будут применять в своих нишевых задачах и получать сильный прирост к профиту.
Надеюсь, к этому времени не запретят заниматься ML без ярлыка от роскомнадзора святейших мудрецов.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/85